
2026.03.27
【中編】SEOの終焉?AIOとAEOで変わる検索トラフィックの実態と次世代マーケティング戦略
AIに選ばれるコンテンツの作り方
<前回のあらすじ>
前編では、AI Overviewの登場によって検索トラフィックが激減している現実と、AIO(AI Overview / AI Optimization)やLLMOと呼ばれるAI最適化という2つの概念についてお伝えしました。
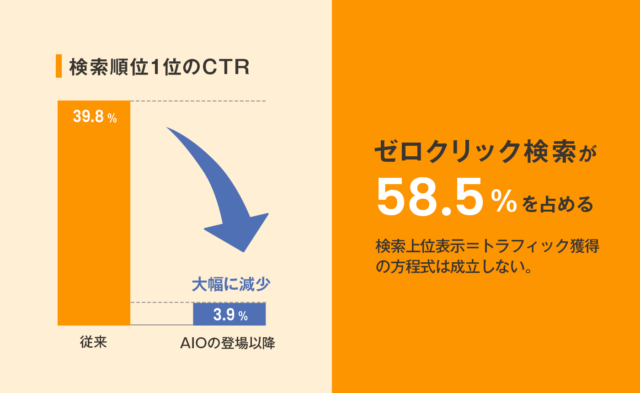
検索順位1位のCTR(クリック率)が39.8%から3.9%へと約10分の1に激減し、ゼロクリック検索が全体の58.5%を占める——この衝撃的な数字は、もはや「検索上位表示 = トラフィック獲得」という方程式が成立しない時代に突入したことを意味しています。
参考: 「AI トラフィックはこの 1 年で 9.7 倍に増加」(February 20, 2026)
では、私たちマーケターは何をすべきなのか?
中編では、この問いに対する実践的な答えを提示していきます。具体的には「AIに選ばれるコンテンツ」をどう作るか、そして新時代のコンテンツ戦略をどう構築するかについて、詳しく解説していきます。
—
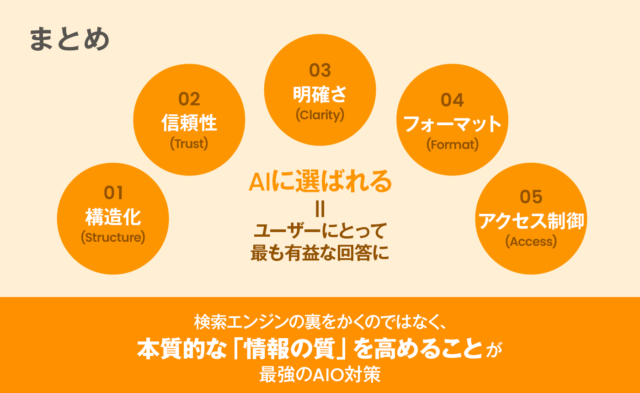
AIに「選ばれる」コンテンツの5つの条件とは?
それでは本題です。AIはどのようなコンテンツを選び、引用し、ユーザーに提示するのでしょうか?
AIの判断基準を理解することが、AEO対策の第一歩です。
条件は大きく分けて5つあります。一つずつ見ていきましょう。
[条件1] 構造化された情報設計
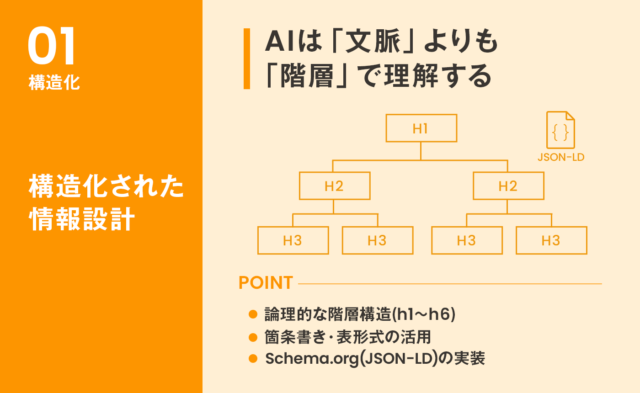
AIは「読みやすさ」よりも「解析しやすさ(=理解しやすさ)」を重視します。
人間は文脈から意味を推測できますが、AIは構造から判断します。
そのため、以下のような構造化された情報設計が不可欠です。
h1〜h6のように、階層を飛ばさずに論理的に構造化することで、AIはコンテンツの全体像を正確に把握します。
人間向けには長文の説明が適している場合でも、AIに対しては(場合によって)箇条書きや表形式の方が情報を抽出しやすくなったります。
スキーママークアップ(Schema.org)の実装も効果的です。
Schema.orgは、Googleやその他の検索エンジンが推奨する構造化データのフォーマットです。
このJSON-LD形式のマークアップを各ページに埋め込むことで、AIはページの内容、著者、公開日などを正確に理解できます。
[条件2] 信頼性の獲得

AI時代において、E-E-A-T(Experience, Expertise, Authoritativeness, Trustworthiness)の重要性はさらに高まっています。
AIは「信頼できる情報源」を優先的に引用します。
なので情報源の選別は極めて慎重に行われます(実際は嘘ついてくることも多いんですけどね)。
そこで重要なのが「E-E-A-T」というGoogleの「このサイトは検索上位にあげよう/下げよう」の基準となる評価アルゴリズムです。
① 経験(Experience)の明示
実際に体験した内容、一次情報であることを明確に示します。
具体的な数値、期間、対象を示すことで、「実際にやってみた」情報であることが伝わります。
<コンテンツ例>
「数字見る」
「お客様の声」
「経験豊富なスタッフによる記事」
など
② 専門性(Expertise)の証明
著者の専門性を明示的に示します。
<コンテンツ例>
「著者プロフィールページへのリンク」
「資格・認定の明記」
「関連する実績」
など
③ 権威性(Authoritativeness)の構築
業界内での認知度や外部からの評価を示します。
<コンテンツ例>
「他サイトからの被リンク(特に権威あるサイトなら尚良し)」
「メディア掲載歴/取材歴」
「受賞歴や認定」
など
④ 信頼性(Trustworthiness)の担保
情報の正確性を保証する要素です。
<コンテンツ例>
「プライバシーポリシー」
「特商法の記載」
「引用元/出典元の明記」
など
[条件3] 簡潔で明確な回答
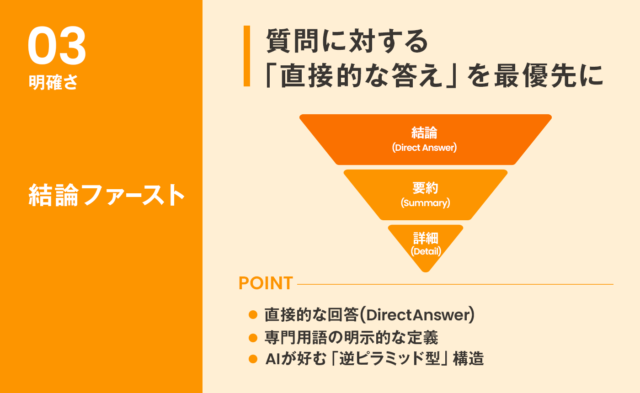
AIが最も好むのは、質問に対して直接的に答えているコンテンツです。
これは「結論ファースト」の文章構造とも言えます。
[従来のSEO記事構造]
1, 導入(問題提起) →2, 背景説明→3, 詳細な解説→4, 結論
[AEO最適化された構造]
1, 結論(直接的な回答)→2, 要約→3, 詳細な解説→4, 補足情報
それに専門用語の適切な説明も重要です。
AIは文脈から意味を推測できますが、”明示的な定義” があればより正確に理解することができます。
[条件4] AIが理解しやすいフォーマット

次は技術的な実装面での最適化です。
JSON-LDによる構造化データ
用途に応じて以下のスキーマタイプも活用しましょう。
FAQPage: よくある質問と回答
HowTo: 手順やチュートリアル
Product: 商品情報
Review: レビュー・評価
BreadcrumbList: パンくずリスト
FAQページの最適化
FAQ形式のコンテンツは、AIにとって最も引用しやすい形式です。
定義リスト(dl/dt/dd)の活用
HTMLの意味論的なタグを正しく使用することも重要です。
[条件5] llms.txt robots.txtの設置

[条件4]とも関連しますが、llms.txtやrobot.txtの設置も効果的なのでは、と言われています。
これらはAIに対して「ここを読んでほしい」、「ここは読まないでほしい」を明示するファイルとなります。
robots.txt
従来のSEOでは主に「不要なページへのアクセスをブロックする用途」で使用されてきました。
しかしAI検索を意識すると、主要なAIクローラーを「許可する=ブロックしない」という設定が重要です。
ウェブサイトの情報を読み取れる状態にしておく ということですね。
以下のようなAIクローラーをブロックしていないか、を確認しておきましょう。
GPTBot(OpenAI): ChatGPTやSearchGPT関連
Google-Extended(Google): Gemini、Vertex AI関連
ClaudeBot(Anthropic): Claude関連
など
学習データとして使われたくないが、検索結果(RAG:検索拡張生成)には表示させたい場合など、将来的にはより細かな設定が求められる可能性があります。
現状「AI検索からの流入を狙うなら、AIボットを許可する」が基本戦略となるのかな、と思っています。
llms.txt
ウェブサイトの情報を効率的に理解するための標準規格です(現状は)。
AIに対して「このサイトはこういうサイトだよ」と明示するもの、と考えてもらえるとわかりやすいかなと思います。
AIが読みやすいようなMArkdown形式でサイトの要約やリンク構造を記載します。
最近のAIエージェントは、サイトを閲覧する際に膨大なタグ、広告、スクリプトも読み込んでしまうため、本来の情報を正しく抽出できないことがあります。
一回の巡回で読み取る情報量が決められているため、余計な情報を読み取らせることで、”本来なら読み込んでほしい情報”を読み込む前に離脱されてしまう(ことがあるため)です。
llms.txtに情報を記載し、ルートディレクトリ(例: https://example.com/llms.txt)にファイルを設置することで、この課題に対処することができる(のでは)と言われています。
※最近Googleもllms.txtを設定している、と話題になりましたね。
なるほど理論はわかったけれど、実際にどう実装すればいいのか?
それを語るには本記事は長くなり過ぎてしまいました。
この続きは次回更新予定の「後編記事」で解説ができればと思います。
それまではしばしお別れということで。
—
aradasではAI時代のWEBサイトの在り方について模索し続けています。
お困りの方、課題を感じていらっしゃる方がおりましたら、お気軽にご連絡くださいませ。
ほいでは。

 関連記事
関連記事



